Reduce Overestimation by Kullback-Leibler Divergence Regularized
Abstract
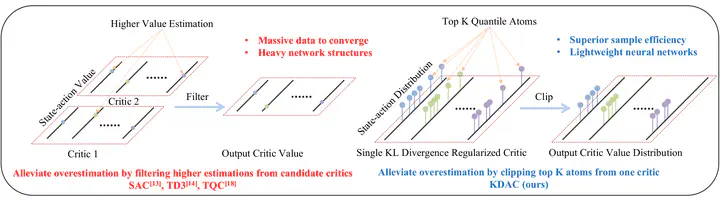
In this work, we propose a novel distributional learning (RL) approach, Kullback-Leibler Divergence regularized Distributional Actor-Critic (KDAC) to tackle the issue of overestimated value function and sample efficiency in the current RL domain. Clipping the high-value quantiles in the distributional value function, the proposed KDAC efficient reduces the overlarge estimated value function from a distributional perspective without employing additional critic networks. The learning process of both actor and critic networks in KDAC is further accelerated and stabilized by introducing the Kullback-Leibler divergence regularization between the current and previous policies. Evaluated by Several benchmark tasks with different levels of complexity, KDAC demonstrates significant superiority in learning capability, overestimation reduction and sample efficiency compared with various traditional and state-of-the-art RL baselines and expands the potential of DRL in more complicated control scenarios.
Supplementary notes can be added here, including code, math, and images.
Mingrong Gong
Graduate Student in SIAT, University of Chinese Academy of Sciences.
My research interest mainly includes trustworthy AI, machine learning, especially domain generalization, and reinforcement learning.